
Python全栈开发-数据分析-01 Numpy详解
发布于2021-07-25 07:09 阅读(1393) 评论(0) 点赞(15) 收藏(2)
Numpy 详解
一. Numpy介绍安装
同样的数值计算,使用Numpy比直接编写Python实现 代码更简洁、性能更高效。
它是目前Python数值计算中最为重要的基础包。
Numpy帮我们处理数值型数据的
在Pandas和机器学习中都会用到Numpy
安装:
1、找到pip3.exe所在的文件夹,复制路径
我的路径是:D:\ruanjian\Python\python3\Scripts
2、按Win+R,输入CMD确定
3、进入后,先输入cd 路径 回车,如图1
4、输入 pip3 install numpy 回车,如图1
5、在Python编译器中,导入模块不报错就证明安装成功了。如下图
二. Numpy 创建多维数组
2.1 利用array函数创建数组对象
# array函数的格式
np.array(object,dtype,ndmin)

案例如下:
import numpy as np
data1 = [1,3,5,7] #列表
w1 = np.array(data1)
print('w1:',w1)
data2 = (2,4,6,8) #元组
w2 = np.array(data2)
print('w2:',w2)
data3 = [[1,2,3,4],[5,6,7,8]] #多维数组
w3 = np.array(data3)
print('w3:',w3)
运行结果为:
w1: [1 3 5 7]
w2: [2 4 6 8]
w3: [[1 2 3 4]
[5 6 7 8]]
2.2 创建特殊数组
2.2.1 arrange函数: 创建等差一维数组
# arange函数格式
np.arange([start,]stop,[step,]dtype)

案例如下:
import numpy as np
w1 = np.arange(10)
print('w1:',w1)
w2 = np.arange(0,1,0.2)
print('w2:',w2)
运行结果为:
w1: [0 1 2 3 4 5 6 7 8 9]
w2: [0. 0.2 0.4 0.6 0.8]
2.2.2 linspace函数:创建等差一维数组,接受元素数量作为参数
# linspace函数格式
np.linspace(start,stop,num,endpoint,retstep=False,dtype=None)

案例如下:
import numpy as np
w = np.linspace(0,1,5)
print(w)
运行结果如下:
[0. 0.25 0.5 0.75 1. ]
2.2.3 logspace函数创建等比一维数组
#logspace函数格式
np.logspace(start,stop,num,endpoint=True,base=10.0,dtype=None)
logspace的参数中,start, stop代表的是10的幂,默认基数base为10,第三个参数元素个数。
案例如下:
import numpy as np
# 生成1-10间的具有5个元素的等比数列
w = np.logspace(0,1,5)
print(w)
运行结果为:
[ 1. 1.77827941 3.16227766 5.62341325 10. ]
2.2.4 ones函数创建指定长度或形状的全1数组
#ones函数格式
np.ones(shape,dtype=None,order='C')
参数:
shape:整数或者整型元组定义返回数组的形状;可以是一个数(创建一维向量),也可以是一个元组(创建多维向量)
dtype : 数据类型,可选定义返回数组的类型。
order : {‘C’, ‘F’}, 可选规定返回数组元素在内存的存储顺序:C(C语言)-rowmajor;F(Fortran)column-major。
案例如下:
import numpy as np
a=np.ones(3) # 返回 array([1. 1. 1.])
print(a)
b=np.ones((2,3))
print(b)
运行结果为:
[1. 1. 1.]
[[1. 1. 1.]
[1. 1. 1.]]
2.2.5 zeros 函数创建指定长度或形状的全0数组
# zeros函数格式
np.zeros(shape,dtype=float,order='C')
参数:
shape:整数或者整型元组定义返回数组的形状;可以是一个数(创建一维向量),也可以是一个元组(创建多维向量)
dtype : 数据类型,可选定义返回数组的类型。
order : {‘C’, ‘F’}, 可选规定返回数组元素在内存的存储顺序:C(C语言)-rowmajor;F(Fortran)column-major。
案例如下:
import numpy as np
a = np.zeros(10)
print(a)
b = np.zeros((2,4))
print(b)
运行结果为:
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]]
2.2.6 ones_like函数创建形状相同的数组
# ones_like函数格式
np.ones_like(a,dtype=float,order='C',subok=True)
参数:
a:用a的形状和数据类型,来定义返回数组的属性
dtype : 数据类型,可选
order顺序 : {‘C’,‘F’,‘A’或’K’},可选,覆盖结果的内存布局。
subok : bool,可选。True:使用a的内部数据类型,False:使用a数组的数据类型,默认为True
案例如下:
import numpy as np
a = np.array([[0, 1, 2],[3, 4, 5]])
b = np.ones_like(a)
print(b)
运行结果为:
[[1 1 1]
[1 1 1]]
2.2.7 full创建指定值的数组
# full函数格式
np.full(shape,fill_value,dtype=None,order='C')
参数:
shape:整数或者整型元组定义返回数组的形状;可以是一个数(创建一维向量),也可以是一个元组(创建多维向量)
fill_value:标量(就是纯数值变量)
dtype : 数据类型,可选定义返回数组的类型。
order : {‘C’, ‘F’}, 可选规定返回数组元素在内存的存储顺序:C(C语言)-rowmajor;F(Fortran)column-major
案例如下:
import numpy as np
a = np.full(3,520)
print(a)
b = np.full((2,4),520)
print(b)
运行结果为:
[520 520 520]
[[520 520 520 520]
[520 520 520 520]]
2.3 使用random模块生成随机数组
在NumPy.random模块中,提供了多种随机数的生成函数。
random函数:生成0-1之间分布的随机数
rand函数:生成服从均匀分布的随机数
randn函数:生成服从正态分布的随机数
randint函数:生成指定范围的随机整数来构成指定形状的数组。
# 用法:
np.random.randint(low, high = None, size = None)
案例如下:
import numpy as np
arr = np.random.randint(100,200,size = (2,4))
print(arr)
运行结果为:
[[107 165 108 119]
[178 158 123 101]]
注 : random模块的常用随机数生成函数

2.4 ndarray对象属性

案例如下:
import numpy as np
warray = np.array([[1,2,3],[4,5,6]])
print('秩为:',warray.ndim)
print('形状为:',warray.shape)
print('元素个数为:',warray.size)
运行结果为:
秩为: 2
形状为: (2, 3)
元素个数为: 6
2.5 多维数组
案例如下:
import numpy as np
a = np.array([1,2,3,4,5,6])
b = np.array(
[
[1,2,3],
[4,5,6]
]
)
print(a)
print(b)
运行结果为:
[1 2 3 4 5 6]
[[1 2 3]
[4 5 6]]
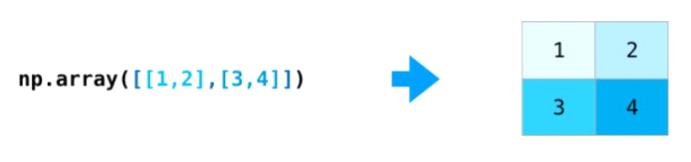
a是一维数组,b是二维数组
一维数组的定义:当数组中每个元素都只带有一个下标时,称这样的数组为一维数组,一维数组实质上是一组相同类型数据的线性集合。
二维数组的定义:二维数组本质上是以数组作为数组元素的数组,即“数组的数组”。
print(a.shape) # 返回一个元组,查看矩阵或者数组的维数(有几个数就是几维),就是几乘几的数组
print(b.shape)
print(a.ndim) # 返回数组维度数目
print(b.ndim)
print(a.size) # 返回数组中所有元素的数目
print(b.size)
print(a.dtype) # 返回数组中所有元素的数据类型
print(b.dtype)
运行结果为:
(6,)
(2, 3)
1
2
6
6
int32
int32

Numpy 不仅可以处理上述的一维数组和二维矩阵(二维数组我们习惯叫它为矩阵),还可以处理任意 N 维的数组,方法也大同小异。


三. 数组变换
3.1 reshape 数组重塑
对于定义好的数组,可以通过reshape方法改变其数据维度
# reshape函数格式
np.reshape(a, newshape, order='C')

案例如下:
import numpy as np
arr1 = np.arange(8)
print(arr1)
arr2 = arr1.reshape(4,2)
print(arr2)
运行结果为:
[0 1 2 3 4 5 6 7]
[[0 1]
[2 3]
[4 5]
[6 7]]
reshape的参数中的其中一个可以设置为-1,表示数组的维度可以通过数据本身来推断。
案例如下:
import numpy as np
arr1 = np.arange(12)
print('arr1:',arr1)
arr2 = arr1.reshape(2,-1)
print('arr2:',arr2)
运行结果为:
arr1: [ 0 1 2 3 4 5 6 7 8 9 10 11]
arr2: [[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]]
与reshape相反的方法是数据散开ravel或数据扁平化flatten
案例如下:
import numpy as np
arr1 = np.arange(12).reshape(3,4)
print('arr1:',arr1)
arr2 = arr1.ravel()
print('arr2:',arr2)
运行结果为:
arr1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
arr2: [ 0 1 2 3 4 5 6 7 8 9 10 11]
需要注意的是,数组重塑不会改变原来的数组
3.2 数组合并
hstack函数:实现横向合并
vstack函数:实现纵向组合是利用vstack将数组纵向合并;
concatenate函数:可以实现数组的横向或纵向合并,参数axis=1时进行横向合并,axis=0时进行纵向合并。
案例如下:
import numpy as np
arr1 = np.arange(6).reshape(3,2)
arr2 = arr1*2
arr3 = np.hstack((arr1,arr2))
print(arr3)
运行结果为:
[[ 0 1 0 2]
[ 2 3 4 6]
[ 4 5 8 10]]
3.3 数组分割
与数组合并相反,hsplit函数、vsplit函数和split函数分别实现数组的横向、纵向和指定方向的分割
案例如下:
import numpy as np
arr = np.arange(16).reshape(4,4)
print('横向分割为:\n',np.hsplit(arr,2))
print('纵向组合为:\n',np.vsplit(arr,2))
运行结果为:
横向分割为:
[array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]), array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
纵向组合为:
[array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
四. 多维数组的索引和切片
4.1 基础索引与切片
4.1.1 一维数组【与Python的列表一样】
import numpy as np
a = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(a[3],a[5],a[-1]) # 返回 3 5 9
print(a[2:4]) # 返回 array([2, 3])
运行结果为:
3 5 9
[2 3]
4.1.2 二维数组
import numpy as np
a = np.array([[0,1,2,3,4],
[5,6,7,8,9],
[10,11,12,13,14],
[15,16,17,18,19]])
print(a[0,0]) # 取数组A的0行0列,返回值0
print(a[-1,2]) # 取最后一行的第2列,返回值17
print(a[2]) # 取第2行所有的列,返回array([10, 11, 12, 13, 14])
print(a[-1]) # 取最后1行
print(a[0:-1]) # 取除了最后1行之外其它所有行
print(a[0:2,2:4]) #取0和1行,2和3列
print(a[:,2]) # 取所有行中的第2列
运行结果为:
0
17
[10 11 12 13 14]
[15 16 17 18 19]
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[[2 3]
[7 8]]
[ 2 7 12 17]
4.2 布尔索引
4.2.1 一维数组
import numpy as np
a = np.arange(10)
print(a)
b = a > 5
print(b) # 返加False和True
print(a[b]) # 返回6 7 8 9
运行结果为:
[0 1 2 3 4 5 6 7 8 9]
[False False False False False False True True True True]
[6 7 8 9]
实例1:把一维数组进行01化处理
假设这10个数字,我想让大于5的数字变成1,小于等于5的数字变成0
a[a<=5] = 0 # 小于5的重新赋值为0
a[a>5] = 1 # 大于5的重新赋值为1
print(a)
运行结果为:
[0 0 0 0 0 0 1 1 1 1]
4.2.2 二维数组
import numpy as np
a = np.arange(1,21).reshape(4,5)
print(a)
b = a>10
print(b) # 返回一个布尔数组,即有行又有列
print(a[b]) # 返回所有为True的对应数字组成的数组,以一维数组展现
运行结果为:
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]]
[[False False False False False]
[False False False False False]
[ True True True True True]
[ True True True True True]]
[11 12 13 14 15 16 17 18 19 20]
案例:
# 例:把第3例大于5的行筛选出来并重新赋值为520
import numpy as np
a = np.arange(1,21).reshape(4,5)
print(a)
print("-"*30)
print(a[:,3]) # 所有行,第3列
print("-"*30)
b = a[:,3] > 5 # 所有行第3列,大于5的
a[a[:,3]>5] = 520
print(a)
运行结果为:
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]
[16 17 18 19 20]]
------------------------------
[ 4 9 14 19]
------------------------------
[[ 1 2 3 4 5]
[520 520 520 520 520]
[520 520 520 520 520]
[520 520 520 520 520]]
4.3 神奇索引
神奇索引:使用整数数组进行数据索引。

a[[2,3,5]] # 返回对应下标的一数组 array([7,9,2])
案例1:
import numpy as np
a = np.arange(36).reshape(9,4)
print(a)
print("*"*15)
print(a[[4,3,0,6]]) # 返回第4行,第3行,第0行,第6行
运行结果为:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]]
***************
[[16 17 18 19]
[12 13 14 15]
[ 0 1 2 3]
[24 25 26 27]]
案例2:
import numpy as np
a = np.arange(32).reshape((8,4))
print(a)
b = a[[1,5,7,2],[0,3,1,2]] # 取第1行第0列,第5行第3列,第7行第1列,第2行第2列
print(b)
运行结果为:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
[ 4 23 29 10]
案例3:
import numpy as np
a = np.arange(36).reshape(9,4)
print(a)
print("*"*30)
print(a[:,[1,2]]) # 取所有行的,第1列和第2列
运行结果为:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]
[32 33 34 35]]
******************************
[[ 1 2]
[ 5 6]
[ 9 10]
[13 14]
[17 18]
[21 22]
[25 26]
[29 30]
[33 34]]
案例4:
import numpy as np
a = np.arange(10)
b = np.array([[0,2],[1,3]])
print(a)
print("*"*30)
print(a[b])
运行结果为:
[0 1 2 3 4 5 6 7 8 9]
******************************
[[0 2]
[1 3]]
案例5:获取数组中最大的前N个数字
# 获取数组中最大的前N个数字
import numpy as np
a = np.random.randint(1,100,10)
print(a)
# 数组.argsort()会返回排序后的下标
# 取最大值对应的3个下标,因为默认升序,所以要用-3,从倒数第3个到最后一个
b = a.argsort()[-3:]
print(b) # 返回的是最大3个数在数组中的下标
# 将下标传给数组
max = a[b]
print(f'最大的三个数是{max}')
运行结果为:
[88 67 68 51 64 33 57 22 92 12]
[2 0 8]
最大的三个数是[68 88 92]
五. 数组的运算
5.1 常用的ufunc函数运算
常用的ufunc函数运算有四则运算比较运算和逻辑运算
5.1.1 四则运算
加(+)、减(-)、乘(*)、除(/)、幂(**) 数组间的四则运算表示对每个数组中的元素分别进行四则运算,所以形状必须相同
案例:
import numpy as np
x = np.array([1,2,3])
y = np.array([4,5,6])
print('数组相加的结果:',x + y)
print('数组相减的结果:',x - y)
print('数组相相乘的结果:',x * y)
print('数组幂运算结果:',x ** y)
运行结果为:
数组相加的结果: [5 7 9]
数组相减的结果: [-3 -3 -3]
数组相相乘的结果: [ 4 10 18]
数组幂运算结果: [ 1 32 729]
5.1.2 比较运算
>、<、、>=、<=、!=。比较运算返回的结果是一个布尔数组,每个元素为每个数组对应元素的比较结果。
案例:
import numpy as np
x = np.array([1,3,6])
y = np.array([2,3,4])
print('比较结果(<):',x<y)
print('比较结果(>):',x>y)
print('比较结果(==):',x==y)
print('比较结果(>=):',x>=y)
print('比较结果(!=):',x!=y)
运行结果为:
比较结果(<): [ True False False]
比较结果(>): [False False True]
比较结果(==): [False True False]
比较结果(>=): [False True True]
比较结果(!=): [ True False True]

5.1.3 逻辑运算
np.any函数表示逻辑“or”,np.all函数表示逻辑“and”, 运算结果返回布尔值。
import numpy as np
x = np.array([1,3,6])
y = np.array([2,3,4])
print(np.all(x == y))
print(np.any(x == y))
运行结果为:
False
True
5.2 广播机制
广播(broadcasting)是指不同形状的数组之间执行算术运算的方式。需要遵循4个原则:
1)让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在左边加1补齐。
2)如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为1的维度进行扩展,以匹配另一个数组的形状。
3)输出数组的shape是输入数组shape的各个轴上的最大值。
4)如果两个数组的形状在任何一个维度上都不匹配,并且没有任何一个维度等于1,则引发异常
简而言之,就是向两个数组每一维度上的最大值靠齐。

案例:
import numpy as np
arr1 = np.array([[0,0,0],[1,1,1],[2, 2,2]])
arr2 = np.array([1,2,3])
print('arr1:\n',arr1)
print('arr2:\n',arr2)
print('arr1+arr2:\n',arr1+arr2)
运行结果为:
arr1:
[[0 0 0]
[1 1 1]
[2 2 2]]
arr2:
[1 2 3]
arr1+arr2:
[[1 2 3]
[2 3 4]
[3 4 5]]
六. Numpy常用random随机函数

6.1 seed 向随机数生成器传递随机状态种子
只要random.seed( * ) seed里面的值一样,那随机出来的结果就一样。所以说,seed的作用是让随机结果可重现。也就是说当我们设置相同的seed,每次生成的
随机数相同。如果不设置seed,则每次会生成不同的随机数。使用同一个种子,每次生成的随机数序列都是相同的。
案例:
import random
random.seed(10)
print(random.random()) # random.random()用来随机生成一个0到1之间的浮点数,包括零。
print(random.random())
print(random.random()) # 这里没有设置种子,随机数就不一样了
运行结果为:
0.5714025946899135
0.4288890546751146
0.5780913011344704
注意:这里不一定就写10,你写几都行,只要写上一个整数,效果都是一样的,写0都行,但是不能为空,为空就相当于没有用seed
seed只限在这一台电脑上,如果换台电脑值就变了
6.2 rand 返回[0,1]之间,从均匀分布中抽取样本
案例:
import numpy as np
a = np.random.rand(3)
print(a)
print('-'*30)
b = np.random.rand(2,3)
print(b)
print('-'*30)
c = np.random.rand(2,3,4)
print(c)
运行结果为:
[0.23890138 0.68326517 0.85139375]
------------------------------
[[0.0455092 0.44022296 0.46564251]
[0.33782986 0.5743118 0.20447685]]
------------------------------
[[[0.68456555 0.01548872 0.66989197 0.38855513]
[0.03761897 0.61350008 0.63589747 0.79511388]
[0.8180318 0.33025986 0.05752598 0.37804437]]
[[0.66896116 0.92360282 0.2335072 0.35792271]
[0.81501829 0.46934585 0.3183461 0.74530283]
[0.43136576 0.25914509 0.5807442 0.86721569]]]
6.3 randn 返回标准正态分布随机数(浮点数)平均数0,方差1 【了解】
randn生成一个从标准正态分布中得到的随机标量,标准正态分布即N(0,1)。
randn(n)和randn(a1,a2,…)的用法和rand相同
案例:
import numpy as np
a = np.random.randn(3)
print(a)
print('-'*30)
b = np.random.randn(2,3)
print(b)
print('-'*30)
c = np.random.randn(2,3,4)
print(c)
print('-'*30)
运行结果为:
[-0.6068222 1.72500931 -0.97008746]
------------------------------
[[-0.13098396 -0.35409372 0.13932285]
[-0.2016921 1.69205721 0.05246772]]
------------------------------
[[[-0.47871393 -0.32813921 0.92560015 -1.31729237]
[ 0.29205161 -0.83561073 0.8140394 0.07418742]
[-0.51890867 0.09398407 1.07040709 -0.28083361]]
[[-0.49503662 0.3847157 0.47767525 -0.43812062]
[ 0.18620117 1.0128372 -0.53846666 -0.66093431]
[ 2.89067126 -0.52338874 1.55560458 0.81670897]]]
------------------------------
6.4 randint 随机整数
案例;
import numpy as np
a = np.random.randint(3)
print(f'随机0至3之间的整数是:{a}')
b = np.random.randint(1,10)
print(f'随机1至10之间的整数是:{b}')
c = np.random.randint(1,10,size=(5,))
print(f'随机1至10之间取5个元素组成一维数组{c}')
d = np.random.randint(1,20,size=(3,4))
print(f'随机1至20之间取12个元素组成二维数组:\n{d}')
e = np.random.randint(1,20,size=(2,3,4))
print(f'随机1至20之间取24个元素组成三维数组:\n{e}')
运行结果为:
随机0至3之间的整数是:1
随机1至10之间的整数是:7
随机1至10之间取5个元素组成一维数组[3 6 7 9 1]
随机1至20之间取12个元素组成二维数组:
[[19 18 12 17]
[ 6 17 6 10]
[ 3 11 18 4]]
随机1至20之间取24个元素组成三维数组:
[[[19 17 17 19]
[17 18 11 13]
[ 8 4 18 19]]
[[14 3 1 1]
[14 4 3 15]
[ 1 10 18 7]]]
6.5 random 生成 0.0至 1.0的随机数
案例:
import numpy as np
a = np.random.random(3)
print(f'生成3个0.0至1.0的随机数:\n{a}')
b = np.random.random(size=(2,3))
print(f'生成2行3列共6个数的0.0至1.0的随机数:\n{b}')
c = np.random.random(size=(3,2,3))
print(f'生成三块2行3列,每块6个数的0.0至1.0的随机数:\n{c}')
运行结果为:
生成3个0.0至1.0的随机数:
[0.04444721 0.75428818 0.28967651]
生成2行3列共6个数的0.0至1.0的随机数:
[[0.82719248 0.71258251 0.82020975]
[0.54337301 0.72674256 0.21173633]]
生成三块2行3列,每块6个数的0.0至1.0的随机数:
[[[0.97152157 0.95011112 0.50318284]
[0.18841304 0.54928768 0.54995733]]
[[0.1289467 0.84730667 0.72302883]
[0.55955508 0.56656654 0.36332886]]
[[0.64167377 0.758676 0.06046674]
[0.85368815 0.3859783 0.73255802]]]
6.6 choice 从一维数组中生成随机数
案例1:
import numpy as np
# 第一参数是一个1维数组,如果只有一个数字那就看成range(5)
# 第二参数是维度和元素个数,一个数字是1维,数字是几就是几个元素
a = np.random.choice(5,3)
print(f'从range(5)中拿随机数,生成只有3个元素的一维数组是:{a}')
运行结果为:
从range(5)中拿随机数,生成只有3个元素的一维数组是:[0 4 4]
案例2:
import numpy as np
b = np.random.choice(5,(2,3))
print(f'从range(5)中拿随机数,生成2行3列的数组是:\n{b}')
运行结果为:
从range(5)中拿随机数,生成2行3列的数组是:
[[3 4 1]
[2 1 3]]
案例3:
import numpy as np
c = np.random.choice([1,2,9,4,8,6,7,5],3)
print(f'从[1,2,9,4,8,6,7,5]数组中拿随机数,3个元素:{c}')
运行结果为:
从[1,2,9,4,8,6,7,5]数组中拿随机数,3个元素:[7 9 9]
案例4:
import numpy as np
d = np.random.choice([1,2,9,4,8,6,7,5],(2,3))
print(f'从[1,2,9,4,8,6,7,5]数组中拿随机数,生成2行3列的数组是:\n{d}')
运行结果为:
从[1,2,9,4,8,6,7,5]数组中拿随机数,生成2行3列的数组是:
[[1 9 4]
[5 1 2]]
6.7 shuffle(数组)把一个数进行随机排列
案例1:
import numpy as np
a = np.arange(10)
print(f'没有随机排列前的一维数组{a}')
np.random.shuffle(一维数组)
print(f'随机排列后的一维数组{a}')
运行结果为:
没有随机排列前的一维数组[0 1 2 3 4 5 6 7 8 9]
随机排列后的一维数组[9 8 5 2 3 4 6 7 0 1]
案例2:
import numpy as np
b = np.arange(20).reshape(4,5)
print(f'没有随机排列前的二维数组\n{b}\n')
np.random.shuffle(二维数组)
print(f'随机排列后的二维数组\n{b}')
运行结果为:
没有随机排列前的二维数组
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
随机排列后的二维数组
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]]
注意:多维数组随机排列只按行随机,列是不变的
案例3:
import numpy as np
c = np.arange(12).reshape(2,2,3)
print(f'没有随机排列前的三维数组\n{c}\n')
np.random.shuffle(三维数组)
print(f'随机排列后的三维数组\n{c}')
运行结果为:
没有随机排列前的三维数组
[[[ 0 1 2]
[ 3 4 5]]
[[ 6 7 8]
[ 9 10 11]]]
随机排列后的三维数组
[[[ 0 1 2]
[ 3 4 5]]
[[ 6 7 8]
[ 9 10 11]]]
七. 通用函数:快速的逐元素数组函数
通用函数也可以称为 ufunc, 是一种在 ndarray 数据中进行逐元素操作的函数。某些简单函数接受了一个或者多个标量数值,并产生一个或多个标量结果,而通用函数就是对这些简单函数的向量化封装。
有很多 ufunc是简单的逐元素转换,比如 sqrt 和exp 函数:就是一元通用函数
案例1:
import numpy as np
a = np.arange(10)
print(a)
print(np.sqrt(a)) # 返回正的平方根
print(np.exp(a)) # 计算每个元素的自然指数值e的x次方
运行结果为:
[0 1 2 3 4 5 6 7 8 9]
[0. 1. 1.41421356 1.73205081 2. 2.23606798
2.44948974 2.64575131 2.82842712 3. ]
[1.00000000e+00 2.71828183e+00 7.38905610e+00 2.00855369e+01
5.45981500e+01 1.48413159e+02 4.03428793e+02 1.09663316e+03
2.98095799e+03 8.10308393e+03]
介绍一下二元通用函数:比如 add和maximum 则会接受两个数组并返回一个数组结尾结果,所以叫做二元通用函数。
案例:
import numpy as np
x = np.random.randn(8)
y = np.random.randn(8)
print(x)
print('--------')
print(y)
print('--------')
print(np.maximum(x ,y)) # 对位比较大小,取大的,生成新的数组返回,逐个元素地将 x和 y 中元素的最大值计算出来
运行结果为:
[-0.34112975 0.20903065 1.06569534 -0.86826813 1.85284987 1.39583388
0.89882297 0.45199836]
--------
[ 1.16112587 1.05322893 0.7356011 1.01727009 -0.961803 0.61278957
-0.31149492 0.63788868]
--------
[1.16112587 1.05322893 1.06569534 1.01727009 1.85284987 1.39583388
0.89882297 0.63788868]



八. 数学和统计方法
| 方法 | 描述 |
|---|---|
| sum | 沿着轴向计算所有元素的累和,0长度的数组累和为0 |
| average | 加权平均,参数可以指定weights |
| prod | 所有元素的乘积 |
| mean | 数学平均,0长度的数组平均值为NaN |
| std,var | 标准差和方差,可以选择自由度调整(默认分母是n) |
| min,max | 最小和最大值 |
| argmin,argmax | 最小和最大值的位置 |
| cumsum | 从0开始元素累积和 |
| cumprod | 从1开始元素累积积 |
| median | 中位数 |
| prercentile | 0-100百分位数 |
| quantile | 0-1分位数 |
8.1 一维数组
案例:
import numpy as np
a = np.array([1,2,3,4,3,5,3,6])
print(f'数组:{a}')
print(np.sum(a))
print(np.prod(a))
print(np.cumsum(a)) # 从0开始元素的累积和
print(np.cumprod(a)) # 从1开始元素的累积积
print(np.max(a))
print(np.min(a))
print(np.argmax(a)) # 最大值所在的下标
print(np.argmin(a)) # 最小值所在的下标
print(np.mean(a)) # 平均数
print(np.median(a)) # 中位数
print(np.average(a)) # 加权平均
counts = np.bincount(a) # 统计非负整数的个数,不能统计浮点数
print(np.argmax(counts)) # 返回众数,此方法不能用于二维数组
运行结果为:
数组:[1 2 3 4 3 5 3 6]
27
6480
[ 1 3 6 10 13 18 21 27]
[ 1 2 6 24 72 360 1080 6480]
6
1
7
0
3.375
3.0
3.375
3
Numpy中没有直接的方法求众数,但是可以这样实现:
import numpy as np
bincount():统计非负整数的个数,不能统计浮点数
counts = np.bincount(nums)
#返回众数
np.argmax(counts)
8.2 二维数组
案例:
import numpy as np
a = np.array([[1,3,6],[9,2,3],[2,3,3]])
print(f'数组:\n{a}')
print('-'*30)
print(np.sum(a))
print(np.prod(a))
print(np.cumsum(a)) # 从0开始元素的累积和,返回一维数组
print(np.cumprod(a)) # 从1开始元素的累积积,返回一维数组
print(np.max(a))
print(np.min(a))
print(np.argmax(a))
print(np.argmin(a))
print(np.mean(a))
print(np.median(a))
print(np.average(a))
运行结果为:
数组:
[[1 3 6]
[9 2 3]
[2 3 3]]
------------------------------
32
17496
[ 1 4 10 19 21 24 26 29 32]
[ 1 3 18 162 324 972 1944 5832 17496]
9
1
3
0
3.5555555555555554
3.0
3.5555555555555554
8.3 Numpy的axis参数的用途

九. 排序
Sort函数对数据直接进行排序,调用改变原始数组,无返回值。

案例:
import numpy as np
arr = np.array([7,9,5,2,9,4,3,1,4,3])
print('原数组:',arr)
arr.sort()
print('排序后:',arr)
运行结果为:
原数组: [7 9 5 2 9 4 3 1 4 3]
排序后: [1 2 3 3 4 4 5 7 9 9]
案例2:
import numpy as np
arr = np.array([[4,2,9,5],[6,4,8,3],[1,6,2,4]])
print('原数组:\n',arr)
arr.sort(axis = 1) #沿横向排序
print('横向排序后:\n',arr)
运行结果为:
原数组:
[[4 2 9 5]
[6 4 8 3]
[1 6 2 4]]
横向排序后:
[[2 4 5 9]
[3 4 6 8]
[1 2 4 6]]
argsort函数和lexsort函数根据一个或多个键值对数据集进行排序。
np.argsort(): 返回的是数组值从小到大的索引值;
np.lexsort(): 返回值是按照最后一个传入数据排序的结果。
案例:
import numpy as np
arr = np.array([7,9,5,2,9,4,3,1,4,3])
print('原数组:',arr)
print('排序后:',arr.argsort())
#返回值为数组排序后的下标排列
运行结果为:
原数组: [7 9 5 2 9 4 3 1 4 3]
排序后: [7 3 6 9 5 8 2 0 1 4]
np.lexsort(): 返回值是按照最后一个传入数据排序的结果。
案例:
import numpy as np
a = np.array([7,2,1,4])
b = np.array([5,2,6,7])
c = np.array([5,2,4,6])
d = np.lexsort((a,b,c))
print('排序后:',list(zip(a[d],b[d],c[d])))
运行结果为:
排序后: [(2, 2, 2), (1, 6, 4), (7, 5, 5), (4, 7, 6)]
十. 重复数据去重

案例1:
import numpy as np
arr = np.arange(5)
print('原数组:',arr)
wy = np.tile(arr,3)
print('重复数据处理:\n',wy)
运行结果为:
原数组: [0 1 2 3 4]
重复数据处理:
[0 1 2 3 4 0 1 2 3 4 0 1 2 3 4]
案例2:
import numpy as np
arr = np.arange(5)
print('原数组:',arr)
wy = np.tile(arr,3)
print('重复数据处理:\n',wy)
arr2 = np.array([[1,2,3],[4,5,6]])
print('重复数据处理:\n',arr2.repeat(2,axis=0))
运行结果为:
原数组: [0 1 2 3 4]
重复数据处理:
[0 1 2 3 4 0 1 2 3 4 0 1 2 3 4]
重复数据处理:
[[1 2 3]
[1 2 3]
[4 5 6]
[4 5 6]]
十一. 文件读写
11.1 读写二进制文件

案例:
import numpy as np
a = np.arange(1,13).reshape(3,4)
print(a)
np.save('arr.npy', a) # np.save("arr", a)
c = np.load( 'arr.npy' )
print(c)
11.2 读写文本文件

11.3 读写CSV文件

原文链接:https://blog.csdn.net/kc44601/article/details/119021340
所属网站分类: 技术文章 > 博客
作者:我想吃麻辣烫
链接:http://www.pythonpdf.com/blog/article/472/a4518e526478b424515f/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)