
Python基础(十四)——文件操作(read、readline、readlines)
发布于2021-07-25 06:42 阅读(709) 评论(0) 点赞(2) 收藏(4)
本文以Python3以上为学习基础。
read、readline、readlines都是取文件内容。
三者有什么区别?
我们先看三个函数的语法格式:
1、read()
fileObject.read([size])
size:如果指定了参数size,就按照该指定长度从文件中读取内容,否则,就读取全文。被读出来的内容,全部塞到一个字符串里面。<通常不使用这个参数>
这样有好处,就是东西都到内存里面了,随时取用,比较快捷;“成也萧何败萧何”,也是因为这点,如果文件内容太多了,内存会吃不消的。
我们来验证一下。
1.1 不指定参数的情况
创建文件zxc.txt,内容如下:

下面读取文件:
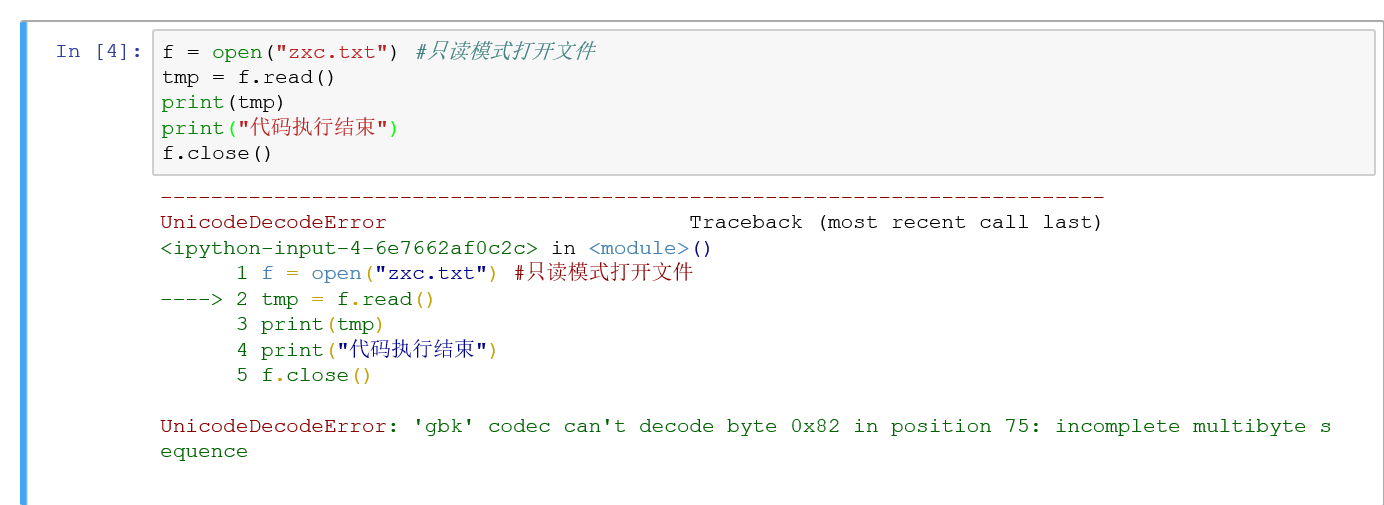
很明显,我们出现了以下错误:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x82 in position 75:
incomplete multibyte sequence
主要原因是因为编码的问题,可能是因为0x82这个字节在gbk编码中没有这个字符,可能原字符是两个字节,在gbk里被解析成了一个字节,导致字符不存在。解决方法有两个,一个是二进制读取,一个是改编编码方式:
二进制读取
这就是我们文件打开方式有二进制的原因。
下面我们进行验证。
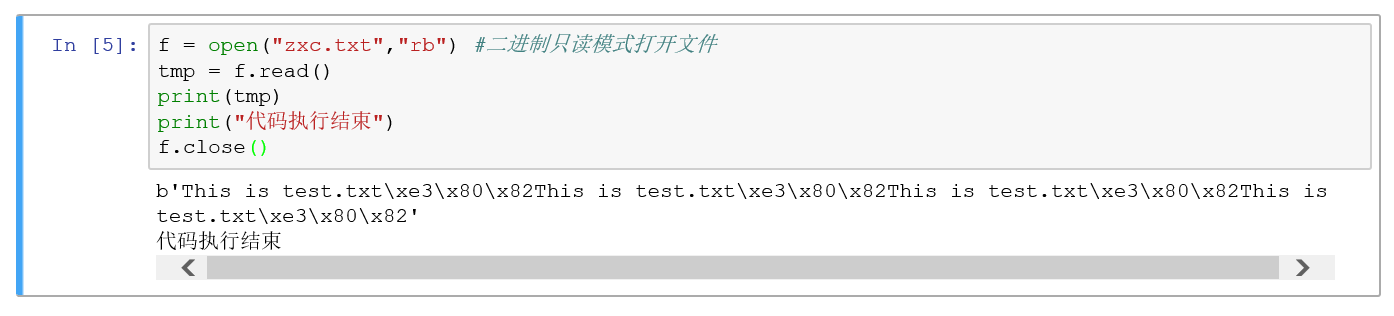
可以看到,二进制就把文件内容读出来了。与原来是中文的句号在gbk里面没有。
虽然参数使用的情况通常不用,但是下面我们还是看看指定参数的情况:
1.2 指定参数的情况
文件内容:
下面指定参数打开文件:

可以看到,固定读取四个字节,得到最开始四个字节:This。
2、readline()
fileObject.readline(size)
size:如果指定了参数size,就按照该指定的读取的字节数从文件中读取内容,否则,就每次读取一行。被读出来的内容,全部塞到一个字符串里面。<通常不使用>
readline()方法每次读取一行,返回的是一个字符串对象,保持当前行的内存。
我们来验证一下。
首先还是一样,没有参数的场合:
2.1 不指定参数的情况
文件内容如下:

下面我们利用readline读取文件内容。
这次为了避免看着麻烦,就把文件中的中文句号给去除了,所以我们直接用读模式r打开就好。

可以看到我们把第一行给都出来了。
其实每操作一次 tmp.readline(),就读取一行,并且将指针向下移动一行。因此,我们如果说利用一种循环,或者说可迭代的来完成对全文的读取。
下面我们看看:
文件内容还是一样:

下面利用循环语句,利用readline函数,循环读取文件内容。

结果显而易见,循环读取每一行的内容,整个文件的内容读取出来了。
这里说一个题外话:
注意:在python中,’\n’表示换行,这也是UNIX系统中的规范。但是,在奇葩的windows中,用’\r\n’表示换行。python是永远滴神,python在处理这个的时候,会自动将’\r\n’转换为’\n’。
很简单我们试试看:
我当前的运行环境是:Windows10、Anaconda3、Python3.5
我们利用二进制把文件打开看看:
文件内容:
我们用readline函数读取一行,打开模式是二进制方式只读。
可以看到,文件的最后的换行符是:\r\n


还是一样,参数通常不用,但是我们来试试有参数的场合:
2.2 指定参数的情况
不多说,直接上示例。
文件内容:

我们用readline函数,指定参数,读取文件:
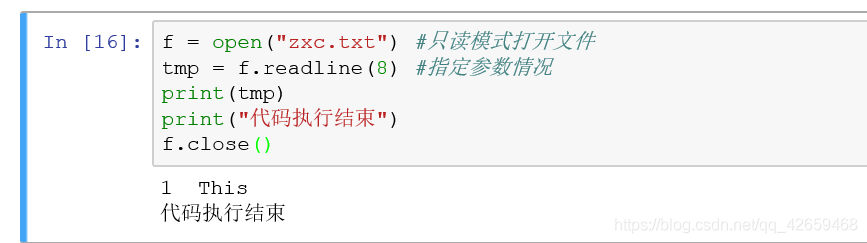
可以看到,返回结果是:1 This(1和This之间是两个空格)
3、readlines()
fileObject.readlines()
我们可以看到readlines函数是没有参数的。
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表。它返回的是以行为单位的列表,即相当于先执行readline(),得到每一行,然后把这一行的字符串作为列表中的元素塞到一个列表中,最后将此列表返回。
该列表可以由 Python 的 for… in … 结构进行处理。
如果碰到结束符 EOF 则返回空字符串。
不多说,我们试试看:
文件内容:

利用readlines函数读取问津内容,并且我们打印读取后的变量类型:

可以看到,最后的记过放在了列表中。
列表中的每个元素就是对应每行的内容,甚至结尾的换行符\n都存在。
既然是列表,那么就可以利用for循环遍历。
以下就是for循环的结果:

我们总结一下三个读取函数:
4、总结
| 函数 | 有无参数 | 返回值 |
|---|---|---|
| read | 有、size:指定读取长度。 | 读取结果返回到字符串里面,并且存在内存中。 |
| readline | 有、size:指定读取长度。 | 以行为单位返回字符串,也就是每次读一行 |
| readlines | 无 | 返回列表,每个列表元素就是一行内容,包括最后的换行符。 |
5、读很大的文件
如果文件太大,就不能用read()或者readlines()一次性将全部内容读入内存,否则内存顶不住的。
但是可以使用while循环和readline()来完成这个任务。一行一行的读。
除此之外还有一个办法:fileinput模块
这个模块后续讲解。
我们直接看用法,一看就懂:
文件内容如下,我们就当文件很大,模拟一下。

利用fileinput模块读取文件:
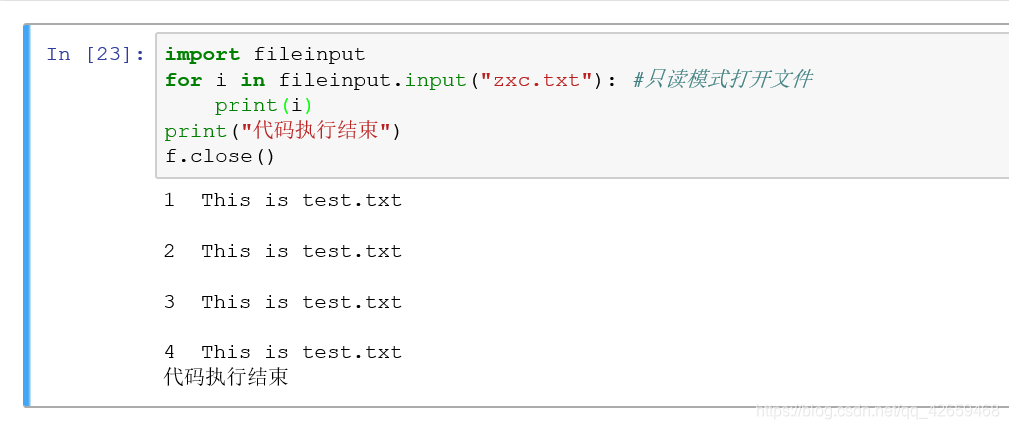
我比较喜欢这个,简洁明快,还用for。
其实还有一个更常用的:
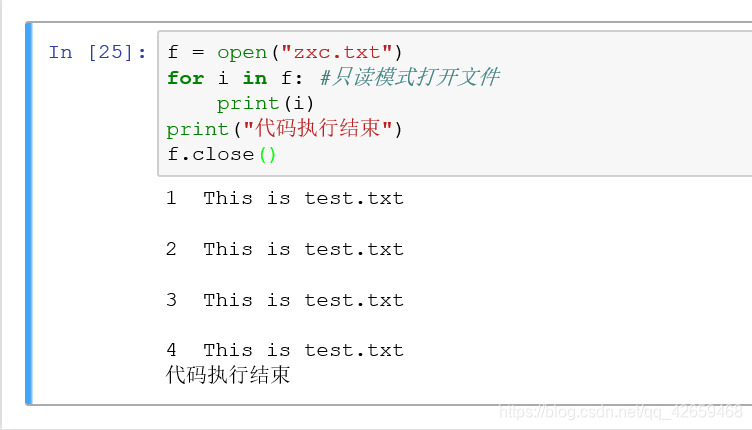
之所以能够如此,是因为file是可迭代的数据类型,直接用for来迭代即可。
原文链接:https://blog.csdn.net/qq_42659468/article/details/118887501
所属网站分类: 技术文章 > 博客
作者:你做的菜有点咸
链接:http://www.pythonpdf.com/blog/article/521/e171aba73bd96236f9a5/
来源:编程知识网
任何形式的转载都请注明出处,如有侵权 一经发现 必将追究其法律责任
昵称:
评论内容:(最多支持255个字符)